Pytorch笔记
Pytorch碎片式笔记,记录一下代码
Pytorch
Pytorch基本训练步骤
import torch
from matplotlib import pyplot as plt
epoch_list = []
loss_list = []
# 1.准备数据
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
# 2.设计模型
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
# 3.构造损失函数和优化器
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 4.周期性训练
# 1. 计算y_pred
# 2. 计算loss值
# 3. Backward(清空梯度)
# 4. 更新参数
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 5.输出结果
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
# 6.绘图
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
Pytorch优化器
- torch.optim.Adagrad
- torch.optim.Adam
- torch.optim.Adamax
- torch.optim.ASGD
- torch.optim.LBFGS
- torch.optim.RMSprop
- torch.optim.Rprop
- torch.optim.SGD
训练名词解释
- Epoch:所有训练样本的一次前向传播和反向传播的过程。
- Batch-Size:一次前向传播和反向传播的训练样本个数。
- Iteration:内层迭代的次数,每次迭代使用 batch size 个样本。 如果有 10000 个样本,batch size=1000, 则 iteration=10
Pytorch读取数据集
# 1.加载数据
batch_size = 512
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./mnist', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./mnist', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
Pytorch训练步骤
1.定义Dataset,加载数据集
需要重写三个方法
__init__ 类被创建会执行(构造器),我们需要在这里初始化数据
__getitem__ 根据索引查询,返回 label 和 image
__len__ 返回 数据集长度
from torch.utils.data import Dataset
from torch.utils.data.dataset import T_co
import os
import cv2 as cv
# 读取我们 label 文件的第一行内容
def read_label(path):
file = open(path, "r", encoding='utf-8')
label = file.readline()
file.close()
return label
class MyDataset(Dataset):
def __init__(self, train_path):
# 给对象赋值,让其他方法也可以获取到
self.train_path = train_path
self.image_path = os.path.join(train_path, 'image')
self.label_path = os.path.join(train_path, 'label')
# 拿到文件夹下所有图片名
self.image_path_list = os.listdir(self.image_path)
def __getitem__(self, index) -> T_co:
# 读取图片
image_name = self.image_path_list[index]
image_path = os.path.join(self.image_path, image_name)
img = cv.imread(image_path)
# 读取图片对应的label
label_name = 'txt'.join(image_name.rsplit(image_name.split('.')[-1], 1))
label_path = os.path.join(self.label_path, label_name)
label = read_label(label_path)
return img, label
def __len__(self):
# 返回数据集长度
return len(self.image_path_list)
# 测试 创建 MyDataset 对象
train_dataset = MyDataset("dataset/train")
val_dataset = MyDataset("dataset/val")
# 拿到下标100的 image 和 label
data_index = 100
img, label = my_dataset[data_index]
# 展示出来 我们这里用到了 __len__
cv.imshow(label + ' (' + str(data_index) + '/' + str(len(my_dataset)) + ')', img)
cv.waitKey(0)
1.函数拟合
1.1一元三次方程拟合sin(x),手动计算梯度
用y = a + b*x + c*x^2 + d*x^3拟合sinx(x)
import torch
import math
from matplotlib import pyplot as plt
import seaborn as sns
dtype = torch.float
device = torch.device("cpu")
# 下边这行代码可以用也可以不用,注释掉就是在CPU上运行
# device = torch.device("cuda:0")
# 创建输入输出数据,这里是x和y代表[-π,π]之间的sin(x)的值
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)
# 随机初始化权重
a = torch.randn((), device=device, dtype=dtype)
b = torch.randn((), device=device, dtype=dtype)
c = torch.randn((), device=device, dtype=dtype)
d = torch.randn((), device=device, dtype=dtype)
# 学习率
learning_rate = 1e-6
# 绘图数据
x_axios = []
y_axios = []
for t in range(2000):
# 前向传播过程,计算y的预测值
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# 计算预测值和真实值的loss
loss = (y_pred - y).pow(2).sum().item()
x_axios.append(t)
y_axios.append(loss)
# 反向传播过程计算 a, b, c, d 关于 loss 的梯度
grad_y_pred = 2.0 * (y_pred - y)
grad_a = grad_y_pred.sum()
grad_b = (grad_y_pred * x).sum()
grad_c = (grad_y_pred * x ** 2).sum()
grad_d = (grad_y_pred * x ** 3).sum()
# 使用梯度下降更新参数
a -= learning_rate * grad_a
b -= learning_rate * grad_b
c -= learning_rate * grad_c
d -= learning_rate * grad_d
print(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
# 绘图
sns.lineplot(x=x_axios, y=y_axios)
plt.show()
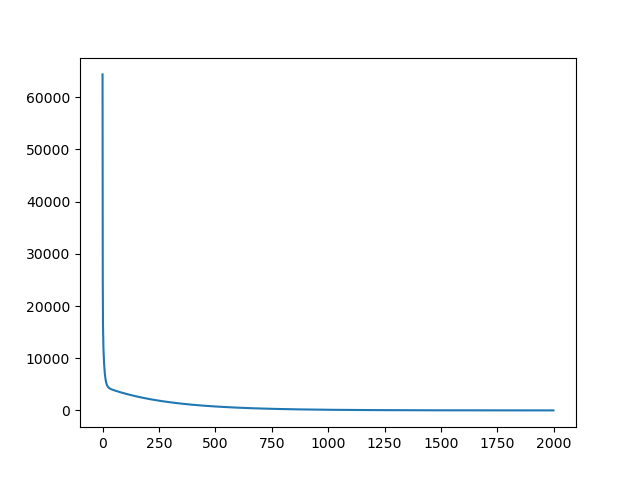
1.2一元三次方程拟合sin(x),自动计算梯度
每个张量都代表计算图上的一个节点,如果x是一个张量,并且你设置好了x.requires_grad=True,那x.grad就是另一个存储x关于某些标量的梯度的张量。
import torch
import math
import seaborn as sns
import matplotlib.pyplot as plt
dtype = torch.float
device = torch.device("cpu")
# 下边这行代码可以用也可以不用,注释掉就是在CPU上运行
# device = torch.device("cuda:0")
# 创建输入输出数据,这里是x和y代表[-π,π]之间的sin(x)的值
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)
# 随机初始化权重
# 注意这里我们设置了requires_grad=True,让autograd自动跟踪计算图的梯度计算
a = torch.randn((), device=device, dtype=dtype, requires_grad=True)
b = torch.randn((), device=device, dtype=dtype, requires_grad=True)
c = torch.randn((), device=device, dtype=dtype, requires_grad=True)
d = torch.randn((), device=device, dtype=dtype, requires_grad=True)
# 学习率
learning_rate = 1e-6
# 绘图数据
x_axios = []
y_axios = []
for t in range(2000):
# 前向过程,计算y的预测值
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# 计算预测值和真实值的loss
loss = (y_pred - y).pow(2).sum()
x_axios.append(t)
y_axios.append(loss.item())
# 使用autograd计算反向过程,调用之后会计算所有设置了requires_grad=True的张量的梯度
# 调用之后 a.grad, b.grad. c.grad d.grad 会存储 abcd关于loss的梯度
loss.backward()
# 使用梯度下降更新参数
# 因为权重设置了requires_grad=True,但是在梯度更新这里我们不需要跟踪梯度,所以加上with torch.no_grad()
with torch.no_grad():
a -= learning_rate * a.grad
b -= learning_rate * b.grad
c -= learning_rate * c.grad
d -= learning_rate * d.grad
# 更新之后将气度清零,以便下一轮运算,不清零的话它会一直累计
a.grad = None
b.grad = None
c.grad = None
d.grad = None
print(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
# 绘图
sns.lineplot(x=x_axios, y=y_axios)
plt.show()
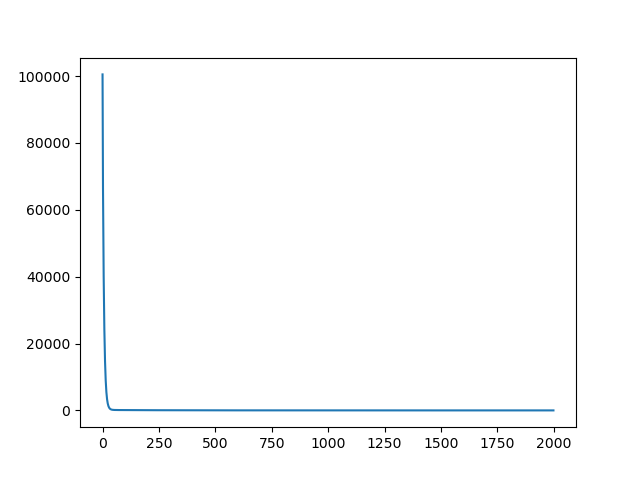
1.3三次勒让德多项式拟合sin(x),自定义forward()和backward()
用y = a + bP( c + dx)模拟y=sin(x),其中P= (5x^3-3x)/2。
import torch
import math
import seaborn as sns
import matplotlib.pyplot as plt
class LegendrePolynomial3(torch.autograd.Function):
def forward(ctx, input):
# 在前向过程中我们接受一个输入张量,并返回一个输出张量
# ctx是一个上下文对象,用于存储反向过程的内容
# 你可以用save_for_backward方法缓存任意在反向计算过程中要用的对象。
ctx.save_for_backward(input)
return 0.5 * (5 * input ** 3 - 3 * input)
def backward(ctx, grad_output):
# 在反向过程中,我们接受一个张量包含了损失关于输出的梯度,我们需要计算损失关于输入的梯度。
input, = ctx.saved_tensors
return grad_output * 1.5 * (5 * input ** 2 - 1)
dtype = torch.float
device = torch.device("cpu")
# 下边这行代码可以用也可以不用,注释掉就是在CPU上运行
# device = torch.device("cuda:0")
# 创建输入输出数据,这里是x和y代表[-π,π]之间的sin(x)的值
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)
# 随机初始化权重
# 注意这里我们设置了requires_grad=True,让autograd自动跟踪计算图的梯度计算
a = torch.full((), 0.0, device=device, dtype=dtype, requires_grad=True)
b = torch.full((), -1.0, device=device, dtype=dtype, requires_grad=True)
c = torch.full((), 0.0, device=device, dtype=dtype, requires_grad=True)
d = torch.full((), 0.3, device=device, dtype=dtype, requires_grad=True)
learning_rate = 5e-6
x_axios = []
y_axios = []
for t in range(2000):
# 我们给我们自定义的autograd起个名叫P3,然后用Function.apply方法调用
P3 = LegendrePolynomial3.apply
# 前向过程计算y,用的是我们自定义的P3的autograd
y_pred = a + b * P3(c + d * x)
# 计算并输出loss
loss = (y_pred - y).pow(2).sum()
x_axios.append(t)
y_axios.append(loss.item())
# 使用autograd计算反向过程
loss.backward()
# 使用梯度下降更新权重
with torch.no_grad():
a -= learning_rate * a.grad
b -= learning_rate * b.grad
c -= learning_rate * c.grad
d -= learning_rate * d.grad
# 在下一轮更新之前将梯度清零,否则会一直累计
a.grad = None
b.grad = None
c.grad = None
d.grad = None
print(f'Result: y = {a.item()} + {b.item()} * P3({c.item()} + {d.item()} x)')
sns.lineplot(x=x_axios, y=y_axios)
plt.show()
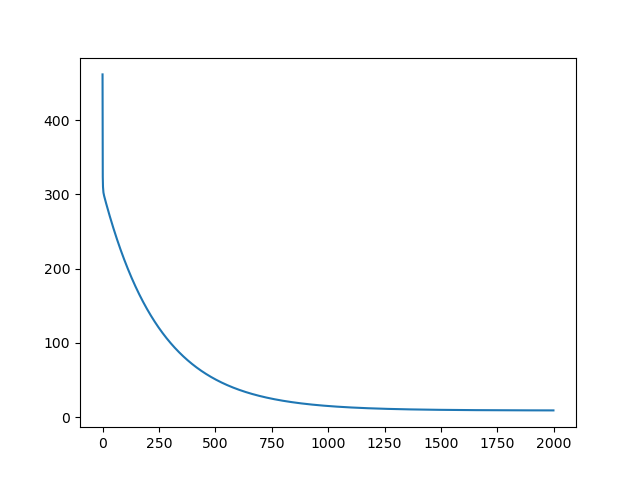
2.波士顿房价
2.1模型训练
## 1.数据集加载
import numpy as np
import re
import torch
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
data = []
# 绘图数据
x_axix = []
y_axix = []
ff = open("housing.data").readlines() # 将数据的每一列都读取出来
for item in ff:
out = re.sub(r"\s{2,}", " ", item).strip()
print(out)
data.append(out.split(" "))
data = np.array(data).astype(np.float64) # 将数据进行类型转换为float
print(data.shape) # 打印数据集大小
## 2.划分数据集
# 这些数据前十三个是x,后一个是y
# 切分数据
Y = data[:, -1]
X = data[:, 0:-1]
# 划分测试集和训练集,定义前496个样本为训练集的样本
X_train = X[0:496, ...]
Y_train = Y[0:496, ...]
X_test = X[496:, ...]
Y_test = Y[496:, ...]
print(X_train.shape)
print(Y_train.shape)
print(X_test.shape)
print(Y_test.shape)
## 3.定义网络
# 定义一个简单的神经网络:只有一个隐藏层,也就是线性层
class Net(torch.nn.Module):
def __init__(self, n_feature, n_output):
super(Net, self).__init__()
self.predict = torch.nn.Linear(n_feature, n_output)
def forward(self, x):
out = self.predict(x)
return out
# 初始化网络
net = Net(13, 1)
## 4.定义loss和optimizer
# loss 采用均方损失
loss_func = torch.nn.MSELoss()
# optimizer
optimizer = torch.optim.SGD(net.parameters(), lr=0.0001)
## 5.训练模型
# training
for i in range(1000):
x_data = torch.tensor(X_train, dtype=torch.float32)
y_data = torch.tensor(Y_train, dtype=torch.float32)
pred = net.forward(x_data)
pred = torch.squeeze(pred)
loss = loss_func(pred, y_data) * 0.001 #缩小loss,防止计算loss为Nan
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录迭代次数和loss的变化
if i % 10 == 0:
x_axix.append(i)
y_axix.append(loss.item())
## 6.测试集loss
# test
x_data = torch.tensor(X_test, dtype=torch.float32)
y_data = torch.tensor(Y_test, dtype=torch.float32)
pred = net.forward(x_data)
pred = torch.squeeze(pred)
loss_test = loss_func(pred, y_data) * 0.001
print("ite:{}, loss_test:{}".format(i, loss))
## 7.保存模型
# 保存模型
torch.save(net, "model.pkl")
# 保存模型参数
torch.save(net.state_dict(), "params.pkl")
## 8.绘图
# 绘制loss曲线
sns.set(style="darkgrid")
sns.relplot(x="iteration", y="loss", kind="line", data=pd.DataFrame({"iteration": x_axix, "loss": y_axix}))
plt.show()
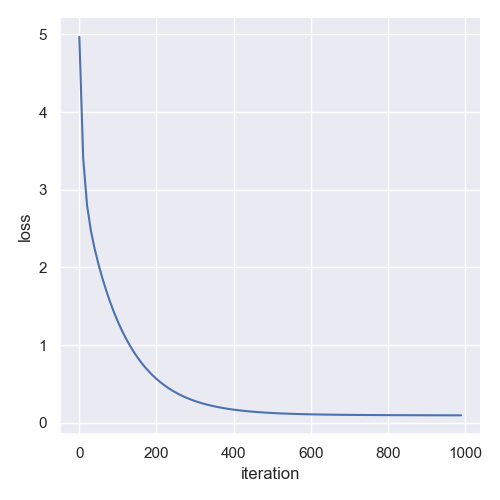
2.2推理代码
import torch
class Net(torch.nn.Module):
def __init__(self, n_feature, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, 100)
self.predict = torch.nn.Linear(100, n_output)
def forward(self, x):
out = self.hidden(x)
out = torch.relu(out)
out = self.predict(out)
return out
data = []
ff = open("housing.data").readlines() # 将数据的每一列都读取出来
for item in ff:
out = re.sub(r"\s{2,}", " ", item).strip()
data.append(out.split(" "))
data = np.array(data).astype(np.float64) # 将数据进行类型转换为float
print(data.shape)
# 这些数据前十三个是x,后一个是y
# 切分数据
Y = data[:, -1]
X = data[:, 0:-1]
# 划分测试集和训练集,定义前496个样本为训练集的样本
X_train = X[0:496, ...]
Y_train = Y[0:496, ...]
X_test = X[496:, ...]
Y_test = Y[496:, ...]
print(X_train.shape)
print(Y_train.shape)
print(X_test.shape)
print(Y_test.shape)
net = torch.load("model.pkl")
loss_func = torch.nn.MSELoss()
# test
x_data = torch.tensor(X_test, dtype=torch.float32)
y_data = torch.tensor(Y_test, dtype=torch.float32)
pred = net.forward(x_data)
pred = torch.squeeze(pred)
loss_test = loss_func(pred, y_data) * 0.001
print("loss_test:{}".format(loss_test))
3.Mnist手写识别
# Imports
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# Create CNN
class CNN(nn.Module):
def __init__(self, in_channels=1, num_classes=10):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(
in_channels=in_channels,
out_channels=8,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1)
)
self.pool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
self.conv2 = nn.Conv2d(
in_channels=8,
out_channels=16,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1)
)
self.fc1 = nn.Linear(16 * 7 * 7, num_classes)
def forward(self, x):
batch = x.shape[0]
return self.fc1(self.pool1(F.relu(self.conv2(self.pool1(F.relu(self.conv1(x)))))).reshape(batch, -1))
# Checking if it is correct shape
model = CNN()
x = torch.rand(64, 1, 28, 28)
print(model(x).shape)
# Set Device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# HyperParams
input_size = 784
num_classes = 10
learning_rate = 0.001
batch_size = 64
num_epochs = 10
# Loading Data
train_data = datasets.MNIST(root="dataset/", train=True, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
test_data = datasets.MNIST(root="dataset/", train=False, transform=transforms.ToTensor(), download=True)
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
# Init Network
model = CNN().to(device)
# Loss and Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(params=model.parameters(), lr=learning_rate)
# Training
for epoch in range(num_epochs):
for batch_idx, (data, labels) in enumerate(train_loader):
data = data.to(device=device)
labels = labels.to(device=device)
scores = model(data)
loss = criterion(scores, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Test
num_correct = 0
num_samples = 0
model.eval()
with torch.no_grad():
for data, labels in test_loader:
data = data.to(device=device)
labels = labels.to(device=device)
scores = model(data)
_, predictions = torch.max(scores, dim=1)
num_correct += (predictions == labels).sum()
num_samples += predictions.size(0)
print(f'Got {num_correct} / {num_samples} with accuracy {float(num_correct) / float(num_samples) * 100:.2f}')
model.train()
# Test and plot 10 random images
model.eval()
with torch.no_grad():
fig, axs = plt.subplots(2, 5, figsize=(12, 6))
axs = axs.flatten()
for i, (data, labels) in enumerate(test_loader):
if i >= 10: # Break after 10 images
break
data = data.to(device=device)
labels = labels.to(device=device)
scores = model(data)
_, predictions = torch.max(scores, dim=1)
# Plot images and predictions
img = data.cpu().numpy().reshape(-1, 28, 28)
axs[i].imshow(img[0], cmap='gray')
axs[i].set_title(f"Label: {labels[0]} - Prediction: {predictions[0]}")
plt.tight_layout()
plt.show()
model.train()
4. Pytorch构建模型三种方式
pytorch构建模型,常用的方式有下面的三种:继承nn.Module基类构建自定义模型,使用nn.Sequential按层顺序构建模型,继承nn.Module基类构建模型,并辅助应用模型容器进行封装。其中第一种方式最为常见,第二种方式最简单,第三种方式灵活但是复杂,具体的可以根据实际任务而定。

4.1 继承nn.Module基类构建自定义模型
下面是一个继承nn.Module基类构建自定义模型的范例。模型中用到的层一般在__init__函数中定义,然后在forward方法中定义模型的正向传播逻辑。
import torch
from torch import nn
from torchkeras import summary
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=32,kernel_size = 3)
self.pool1 = nn.MaxPool2d(kernel_size = 2,stride = 2)
self.conv2 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5)
self.pool2 = nn.MaxPool2d(kernel_size = 2,stride = 2)
self.dropout = nn.Dropout2d(p = 0.1)
self.adaptive_pool = nn.AdaptiveMaxPool2d((1,1))
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(64,32)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(32,1)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.dropout(x)
x = self.adaptive_pool(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
y = self.sigmoid(x)
return y
net = Net()
print(net)
summary(net, input_shape=(3, 32, 32))
4.2使用nn.Sequential按层顺序构建模型
使用nn.Sequential按层顺序构建模型无需定义forward方法。仅仅适合于简单的模型。这个就类似于keras里面的sequence方法。
4.2.1 利用add_module方法
from torch import nn
from torchkeras import summary
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=3,out_channels=32,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(64,32))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(32,1))
net.add_module("sigmoid",nn.Sigmoid())
print(net)
summary(net, input_shape=(3, 32, 32))
4.2.2 利用变长参数
这种方式构建时不能给每个层指定名称
from torch import nn
from torchkeras import summary
net = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size = 3),
nn.MaxPool2d(kernel_size = 2,stride = 2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5),
nn.MaxPool2d(kernel_size = 2,stride = 2),
nn.Dropout2d(p = 0.1),
nn.AdaptiveMaxPool2d((1,1)),
nn.Flatten(),
nn.Linear(64,32),
nn.ReLU(),
nn.Linear(32,1),
nn.Sigmoid()
)
print(net)
summary(net, input_shape=(3, 32, 32))
4.2.3 利用OrderedDict
from torch import nn
from torchkeras import summary
from collections import OrderedDict
net = nn.Sequential(OrderedDict(
[("conv1",nn.Conv2d(in_channels=3,out_channels=32,kernel_size = 3)),
("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2)),
("conv2",nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5)),
("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2)),
("dropout",nn.Dropout2d(p = 0.1)),
("adaptive_pool",nn.AdaptiveMaxPool2d((1,1))),
("flatten",nn.Flatten()),
("linear1",nn.Linear(64,32)),
("relu",nn.ReLU()),
("linear2",nn.Linear(32,1)),
("sigmoid",nn.Sigmoid())
])
)
print(net)
summary(net, input_shape=(3, 32, 32))
4.3 继承nn.Module基类构建模型并辅助应用模型容器进行封装
当模型的结构比较复杂的时候,我们可以应用模型容器(nn.Sequential, nn.ModuleList, nn.ModuleDict)对模型的部分结构进行封装,这样做会让模型整体更加有层次感,有时候也能减少代码量。
4.3.1 nn.Sequential作为模型容器
from torch import nn
from torchkeras import summary
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Dropout2d(p=0.1),
nn.AdaptiveMaxPool2d((1, 1))
)
self.dense = nn.Sequential(
nn.Flatten(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv(x)
y = self.dense(x)
return y
net = Net()
print(net)
summary(net, input_shape=(3, 32, 32))
4.3.2 nn.ModuleList作为模型容器
from torch import nn
from torchkeras import summary
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layers = nn.ModuleList([
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Dropout2d(p=0.1),
nn.AdaptiveMaxPool2d((1, 1)),
nn.Flatten(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid()]
)
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
net = Net()
print(net)
summary(net, input_shape=(3, 32, 32))
4.3.3 nn.ModuleDict作为模型容器
from torch import nn
from torchkeras import summary
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layers_dict = nn.ModuleDict({"conv1": nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3),
"pool": nn.MaxPool2d(kernel_size=2, stride=2),
"conv2": nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5),
"dropout": nn.Dropout2d(p=0.1),
"adaptive": nn.AdaptiveMaxPool2d((1, 1)),
"flatten": nn.Flatten(),
"linear1": nn.Linear(64, 32),
"relu": nn.ReLU(),
"linear2": nn.Linear(32, 1),
"sigmoid": nn.Sigmoid()
})
def forward(self, x):
layers = ["conv1", "pool", "conv2", "pool", "dropout", "adaptive",
"flatten", "linear1", "relu", "linear2", "sigmoid"]
for layer in layers:
x = self.layers_dict[layer](x)
return x
net = Net()
print(net)
summary(net, input_shape=(3, 32, 32))
5.Cuda加速
关于使用 GPU 有一些小小的建议:
- gpu 运算很快,但是运算量小时,不能体现出它的优势,因此一些简单的操作可以使用 cpu 完成
- 数据在 cpu 和 gpu 之间的传递会比较耗时,应当尽量避免
- 在进行低精度的计算时,可以考虑使用 HalfTensor 时,相比较 FloatTensor 能节省一半的显存,但需要注意数值溢出的情况
注:大部分的损失函数也都属于 nn.Module,但在使用 gpu 时,很多时候我们都忘记使用它的 .cuda 方法,在大多数情况下不会保存,因为损失函数没有可学习的参数。但在某些情况下会出错,为了保险起见也为了代码更规范,也应该记得调用 criterion.cuda,下面举例说明:
import torch
import torch.nn.functional as functional
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
# global definitions
BATCH_SIZE = 64
MNIST_PATH = "../Data/MNIST"
# transform sequential
transform = transforms.Compose([
transforms.ToTensor(),
# mean std
transforms.Normalize((0.1307,), (0.3081,))
])
# training dataset
train_dataset = datasets.MNIST(root=MNIST_PATH,
train=True,
download=True,
transform=transform)
# training loader
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=BATCH_SIZE)
# test dataset
test_dataset = datasets.MNIST(root=MNIST_PATH,
train=False,
download=True,
transform=transform)
# test loader
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=BATCH_SIZE)
class FullyNeuralNetwork(torch.nn.Module):
def __init__(self):
super().__init__()
# layer definitions
self.layer_1 = torch.nn.Linear(784, 512) # 28 x 28 = 784 pixels as input
self.layer_2 = torch.nn.Linear(512, 256)
self.layer_3 = torch.nn.Linear(256, 128)
self.layer_4 = torch.nn.Linear(128, 64)
self.layer_5 = torch.nn.Linear(64, 10)
def forward(self, data):
# transform the image view
x = data.view(-1, 784)
# do forward calculation
x = functional.relu(self.layer_1(x))
x = functional.relu(self.layer_2(x))
x = functional.relu(self.layer_3(x))
x = functional.relu(self.layer_4(x))
x = self.layer_5(x)
# return results
return x
def train(epoch, model, criterion, optimizer):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# convert data to GPU
inputs, target = data
inputs = inputs.cuda()
target = target.cuda()
# clear gradients
optimizer.zero_grad()
# forward, backward, update
outputs = model(inputs)
criterion.cuda()
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# print loss
running_loss += loss.cpu().item()
if batch_idx % 300 == 0:
print('[%d, %5d] loss: %.3f' % (epoch, batch_idx, running_loss / 300))
running_loss = 0.0
def test(model):
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
# convert data to gpu
images = images.cuda()
# test
outputs = model(images)
_, predicated = torch.max(outputs.data, dim=1)
# count the accuracy
total += labels.size(0)
predicated = predicated.cpu()
correct += (predicated == labels).sum().item()
print("Accuracy on test set: %d %%" % (100 * correct / total))
if __name__ == "__main__":
# full neural network model
cpu_model = FullyNeuralNetwork()
gpu_model = cpu_model.cuda()
# LOSS function
criterion = torch.nn.CrossEntropyLoss()
# parameters optimizer
# stochastic gradient descent
optimizer = optim.SGD(gpu_model.parameters(), lr=0.1, momentum=0.5)
# training and do gradient descent calculation
for epoch in range(5):
# training data
train(epoch, gpu_model, criterion, optimizer)
# test model
test(gpu_model)
6.Transforms
Transforms 是 torchvision 下的一个子模块,主要用于对图像进行转换等一系列预处理操作,其主要目的是对图像数据进行增强,进而提高模型的泛化能力。对图像预处理操作有数据中心化,缩放,裁剪,旋转,翻转,填充,添加噪声,灰度变换,线性变换,仿射变换,亮度,饱和度,对比变换等
from torchvision import transforms
import cv2 as cv
# 取一张图片
img = cv.imread("test.jpg")
transforms.ToTensor()
将图片转为Tensor
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
transforms.Resize()
将输入图像的大小调整为给定的大小
resize_trans = transforms.Resize((300, 300))
resize_img = resize_trans(img)
transforms.ToPILImage()
将输入图像转成PIL的Image类型
PILImage_trans = transforms.ToPILImage()
PILImage_img = PILImage_trans(img)
transforms.Compose()
相当于一个流式操作,可以指定多个transforms
transforms.Compose({tensor_trans, resize_trans, PILImage_trans})
当数据集是28x28大小,但是输入图像是224x224大小时则需要进行数据增强
data_transform = {
# 进行数据增强的处理
"train": transforms.Compose([transforms.RandomResizedCrop(224),#将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小;
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
}
transforms.Normalize()
归一化,标准化,处理后将数据标准化,即均值为0,标准差为1,使模型更容易收敛。
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
DataLoader
创建DataLoader对象,可以指定下列主要参数
dataset: 数据集 # batch_size: 一批多少条数据
shuffle: 这次数据读完后,下次是否洗牌
sampler: 抽取器,默认是随机抽取
num_workers: 多少子进程装载数据,默认0表示数据将在主进程中加载。
drop_last: 最后一批,不够batch_size的数量,是否舍掉
val_dataLoader = DataLoader(dataset=val_data, batch_size=64, shuffle=True, sampler=None, num_workers=0, drop_last=False)
参考
- Pytorch
- Pytorch基本训练步骤
- Pytorch优化器
- 训练名词解释
- Pytorch读取数据集
- Pytorch训练步骤
- 1.定义Dataset,加载数据集
- 1.函数拟合
- 1.1一元三次方程拟合sin(x),手动计算梯度
- 1.2一元三次方程拟合sin(x),自动计算梯度
- 1.3三次勒让德多项式拟合sin(x),自定义forward()和backward()
- 2.波士顿房价
- 2.1模型训练
- 2.2推理代码
- 3.Mnist手写识别
- 4. Pytorch构建模型三种方式
- 4.1 继承nn.Module基类构建自定义模型
- 4.2使用nn.Sequential按层顺序构建模型
- 4.2.1 利用add_module方法
- 4.2.2 利用变长参数
- 4.2.3 利用OrderedDict
- 4.3 继承nn.Module基类构建模型并辅助应用模型容器进行封装
- 4.3.1 nn.Sequential作为模型容器
- 4.3.2 nn.ModuleList作为模型容器
- 4.3.3 nn.ModuleDict作为模型容器
- 5.Cuda加速
- 6.Transforms
- transforms.ToTensor()
- transforms.Resize()
- transforms.ToPILImage()
- transforms.Compose()
- transforms.Normalize()
- DataLoader
- 参考